


AI基建,光板铜电—光&铜篇主流算力芯片Scale up&out方案全解析
【原报告在线阅读和下载】:20251228【MKList.com】电子行业深度报告:AI基建,光板铜电—光&铜篇主流算力芯片Scale up&out方案全解析 | 四海读报
【迅雷批量下载】:链接:https://pan.xunlei.com/s/VOXJ23RJHhoECPL5FRrVathfA1 提取码:umqb
【夸克批量下载】:链接:https://pan.quark.cn/s/fe42cc605010 提取码:j4Vv

1. 一段话总结
AI基建算力互联核心围绕Scale up(柜内高密度互联) 与Scale out(集群超大规模扩展) 两大方向,英伟达、谷歌、亚马逊、Meta四大科技巨头均采用“光+铜”双线方案——铜缆凭借短距低耗低成本优势,成为柜内互联最优解(如Meta采用112G PAM4铜缆实现204.8Tbps对称带宽);光模块随集群扩容需求激增,与GPU配比最高达1:12,800G/1.6T产品成主流,光芯片缺口凸显,2026年商用GPU与CSP ASIC大规模部署将驱动光铜互联需求量价齐升,重点关注光芯片与铜缆赛道。
2. 思维导图
3. 详细总结
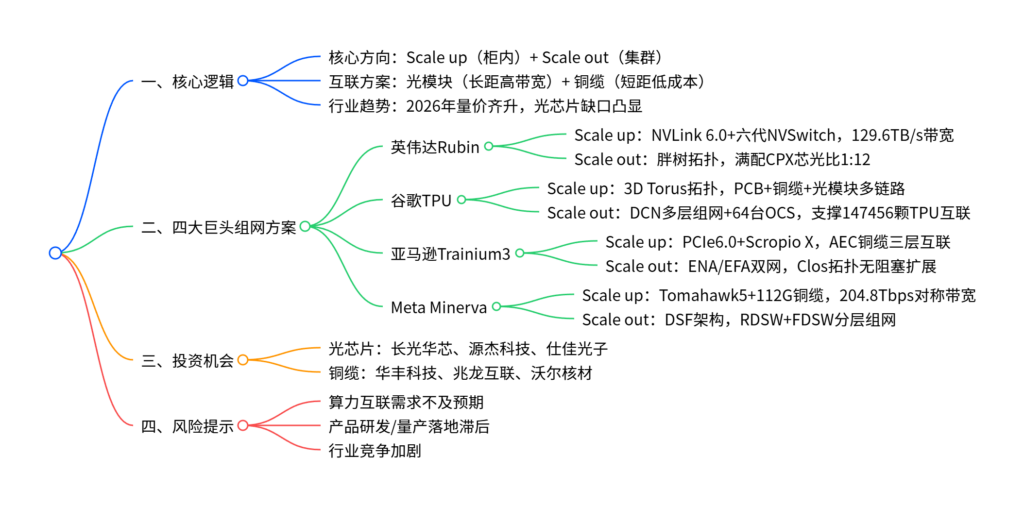
一、行业核心框架
-
核心目标:AI算力集群需同时满足高密度互联(Scale up) 与超大规模扩展(Scale out) ,平衡带宽、时延、成本三大核心诉求。
-
技术路径:“光+铜”双线共振
- 铜缆:适配柜内短距互联,优势为低时延、低功耗、低成本,主流规格为112G PAM4、AEC铜缆。
- 光模块:适配集群长距互联,优势为高带宽、无阻塞,主流规格为800G/1.6T,与GPU配比持续提升。
-
行业催化剂:2026年商用GPU持续放量,CSP ASIC进入大规模部署阶段,超节点与集群扩容驱动互联需求爆发。
二、四大科技巨头组网方案详解
| 企业 | Scale up(柜内互联)核心配置 | Scale out(集群扩展)核心配置 | 关键指标 |
|---|---|---|---|
| 英伟达Rubin | 18个计算托盘(72颗双GPU模组)+9个交换托盘(36颗六代NVSwitch),NVLink 6.0赋能 | 胖树拓扑,Tor/叶/脊三层组网,Spectrum 6交换机(102.4Tbps带宽) | 芯光比最高1:12(满配CPX) |
| 谷歌TPU | 64卡机柜(16个托盘),3D Torus拓扑,PCB(板内)+铜缆/AOC(柜内)+光模块(柜外)多链路 | DCN分层架构,9216 ICI POD为基础模块,64台300×300端口OCS实现全局互联 | 支持147456颗TPU集群 |
| 亚马逊Tr3 | 36个计算托盘(144颗Tr3)+20个交换托盘(40颗Scropio X),PCIe6.0+AEC铜缆三层互联 | ENA/EFA双网分工,Clos拓扑,12.8T/25.6T交换机,集群规模线性扩展 | 支持131072颗Tr3集群 |
| Meta Minerva | 16个MTIA计算托盘+4个Tomahawk5交换托盘,112G PAM4铜缆背板 | DSF解耦架构,RDSW(Jericho3)+FDSW(Ramon3)分层,1:1收敛比 | 204.8Tbps对称带宽 |
(一)英伟达Rubin:高带宽低时延标杆
- Scale up:计算侧与交换侧单向带宽均达129.6TB/s,通过224G差分对AEC铜缆实现GPU与NVSwitch互联,带宽密度较前代翻倍。
- Scale out:采用无收敛胖树拓扑,9216颗GPU集群需288台Tor交换机+288台叶交换机+144台脊交换机,满配CPX时总光模块需求110592个,芯光比1:12。
(二)谷歌TPU:3D Torus+OCS创新方案
- Scale up:64颗TPU通过3D Torus拓扑互联,每颗TPU配置6个800G端口,其中160个端口用铜缆/AOC连接柜内不同板卡,128个端口通过PCB连接相邻TPU,整机柜光模块用量96个(芯光比1:1.5)。
- Scale out:4个聚合模块(含144个64卡机柜)通过64台OCS设备互联,2304台Spine交换机实现全局动态非阻塞传输,端到端时延显著降低。
(三)亚马逊Trainium3:高密度+灵活扩展
- Scale up:单颗Tr3配置144个活跃NeuronLink4端口,64个用于PCB板内互联,80个用于背板铜缆互联,16个用于跨机架铜缆互联,整机柜需180根背板AEC铜缆+36根跨机架AEC铜缆。
- Scale out:ENA承载南北向流量(400G Nitro-v6网卡),EFA承载东西向AI训练流量,8192台Tor交换机上联4608台Leaf交换机,支撑超大规模集群无阻塞扩展。
(四)Meta Minerva:超大规模AI训练优化
- Scale up:16颗MTIA通过8个2×800G端口接入4颗Tomahawk5交换机,铜缆背板提供1024对高速链路,总带宽204.8Tbps,实现计算与交换侧对称互联。
- Scale out:DSF架构通过RDSW(机柜级)与FDSW(Fabric级)解耦调度与交换,18432颗MTIA集群需1440台FDSW+720台SDSW,光模块总需求184320个(800G规格)。
三、投资机会与风险
-
核心赛道:
- 光芯片:800G/1.6T光模块放量导致芯片缺口,受益企业为长光华芯、源杰科技、仕佳光子。
- 铜缆:112G PAM4铜缆、AEC铜缆需求激增,受益企业为华丰科技、兆龙互联、沃尔核材。
-
风险提示:
- 算力建设投入不及预期,导致互联产品采购需求放缓。
- 光模块/铜缆产品研发或量产落地滞后,错失市场机遇。
- 行业竞争加剧,企业市场份额与盈利能力承压。
4. 关键问题
问题1:四大科技巨头Scale up(柜内互联)的核心差异的是什么?铜缆在其中的应用共性与规格有哪些?
答案:核心差异集中在拓扑架构与带宽配置:英伟达采用“NVLink+NVSwitch”对称带宽方案,谷歌用3D Torus多链路互联,亚马逊依托PCIe6.0+Scropio X交换芯片,Meta聚焦Tomahawk5+铜缆背板对称互联。铜缆应用共性为短距互联最优解,适配板内、背板、跨机架场景;规格集中为112G PAM4差分铜缆、AEC铜缆,核心满足低时延、低成本诉求,如Meta用112G铜缆实现204.8Tbps带宽,亚马逊用AEC铜缆支撑PCIe6.0三层互联。
问题2:AI集群Scale out(集群扩展)中,光模块的需求放量逻辑是什么?四大巨头的芯光比最高可达多少?
答案:光模块放量核心逻辑是集群规模扩容+无阻塞传输需求:AI训练需海量参数高频同步,无收敛拓扑(胖树/Clos)要求上下行带宽1:1配比,交换机端口与光模块用量随GPU数量线性增长。四大巨头中,英伟达Rubin满配CPX时芯光比最高达1:12(9216颗GPU对应110592个光模块);谷歌TPU柜内芯光比1:1.5,集群级芯光比随规模提升至1:2+;Meta 18432颗MTIA集群需184320个800G光模块,芯光比1:10;亚马逊Tr3万卡集群芯光比约1:8。
问题3:2026年光铜互联赛道的核心增长驱动力是什么?光芯片与铜缆赛道的投资逻辑有何不同?
答案:核心增长驱动力是商用GPU持续放量+CSP ASIC大规模部署:2026年AI基建进入超节点与大规模集群落地期,Scale up催生铜缆需求,Scale out拉动光模块需求,形成“一铜一光”双线共振。投资逻辑差异:① 光芯片:受益于800G/1.6T光模块渗透率提升,行业供需缺口凸显,核心看技术壁垒与量产能力;② 铜缆:受益于112G PAM4、AEC等高端规格替代,聚焦短距互联场景,核心看客户认证与产能规模,直接受益于柜内高密度互联需求爆发。











暂无评论内容