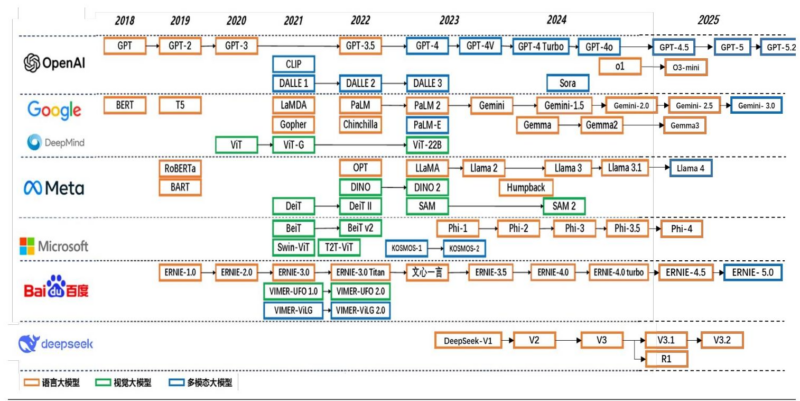


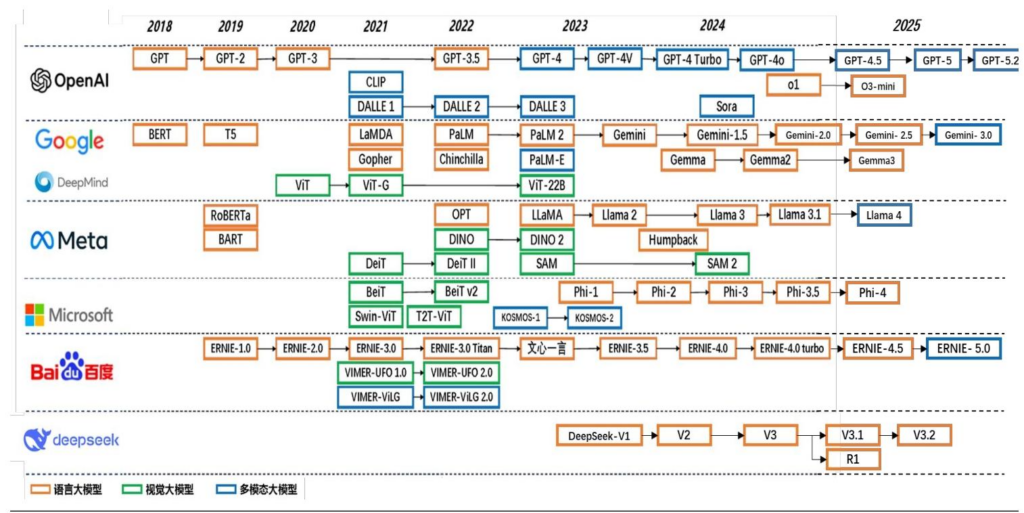
超节点:光、液冷、供电、芯片的全面升级
【原报告在线阅读和下载】:20260129【MKList.com】通信行业深度报告:超节点:光、液冷、供电、芯片的全面升级 | 四海读报
【迅雷批量下载】:链接:https://pan.xunlei.com/s/VOXJ23RJHhoECPL5FRrVathfA1 提取码:umqb
【夸克批量下载】:链接:https://pan.quark.cn/s/fe42cc605010 提取码:j4Vv
1. 一段话总结
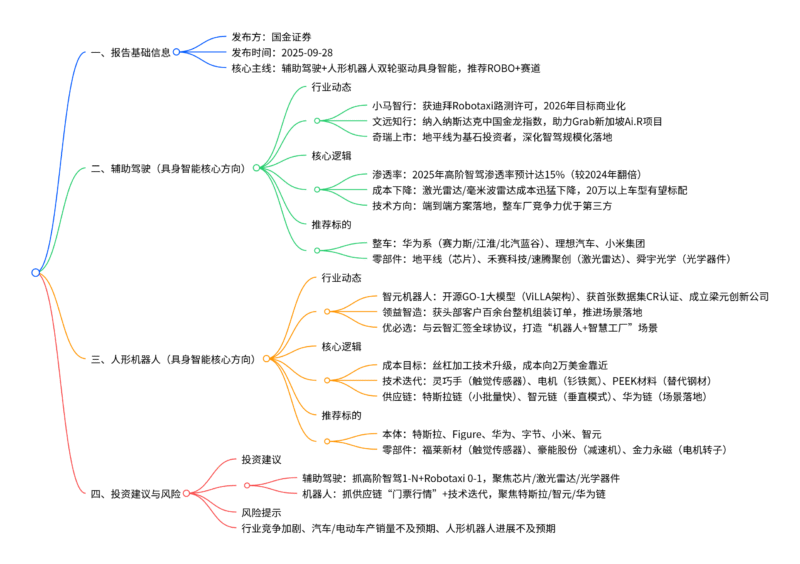
超节点(SuperPod)作为AI大模型算力需求爆发下的必然产物,通过Scale Up(纵向扩展) 与Scale Out(横向扩展)结合,将分散算力芯片整合为逻辑上的“大型GPU/ASIC”,核心依赖组网拓扑(胖树/Mesh/Torus) 与互联协议(NVLink/UB/OISA) 创新;其架构升级直接拉动光通信、液冷、供电、芯片四大环节需求,华为Atlas 900 A3/A960等国产超节点实现性能突破(CloudMatrix 384集群BF16性能为NVL72的1.7倍),行业投资聚焦“网络端+AIDC+计算端”三条主线,推荐中际旭创、英维克、盛科通信等标的,需警惕AI发展不及预期等风险。
2. 思维导图(mindmap)

3. 详细总结
一、核心驱动:AI大模型催生超节点时代
- 需求背景:AI模型参数从千亿级迈向万亿级(如Qwen3-Max超1T参数),单卡/GPU服务器无法承载,训练/推理需千卡→万卡→百万卡级集群。
- 技术痛点:传统Scale Out架构依赖以太网互联,跨服务器通信带宽低、时延高,制约分布式训练效率,“通信墙”成为核心瓶颈。
- 超节点定义:通过Scale Up纵向扩展(域内高带宽互联)+ Scale Out横向扩展(跨域组网),将同一高带宽域(HBD)内的算力芯片整合为逻辑“超级GPU”,突破单机8卡瓶颈。
二、超节点架构:组网拓扑与互联协议创新
(一)组网拓扑:三大主流类型
| 拓扑类型 | 核心特点 | 代表案例 | 关键参数 |
|---|---|---|---|
| 胖树拓扑 | 无阻塞互联,带宽池化 | 英伟达NVL72/NVL576 | NVL72总带宽130TB/s,支持72颗GPU |
| Mesh类拓扑 | 多维全互联,短路径优先 | 华为2D Fullmesh、AMD MI350 | 华为柜内64卡互联,节点间带宽衰减<3% |
| Torus拓扑 | 故障域隔离,可靠性高 | Google TPU v4/v5p | TPU v7支持9216颗芯片集群 |
(二)互联协议:从私有到开源开放
| 协议类型 | 发起方 | 核心优势 | 关键性能 |
|---|---|---|---|
| NVLink | 英伟达 | 高带宽低时延,2025年开放 | Blackwell时代单卡带宽1.8TB/s |
| UB(灵衢) | 华为 | 支持百ns~us级时延,融合组网 | 单芯片双向带宽392GB/s |
| OISA | 中国移动+48家厂商 | 支持1024张AI芯片,TB/s级带宽 | 互联时延缩短至数百纳秒 |
| SUE | 博通 | 基于以太网,单跳支持1024个XPU | 往返延迟(RTT)<2微秒 |
| UAlink | AMD/谷歌/英特尔等 | 开放式标准,支持1024个加速器 | 单通道速率200GT/s |
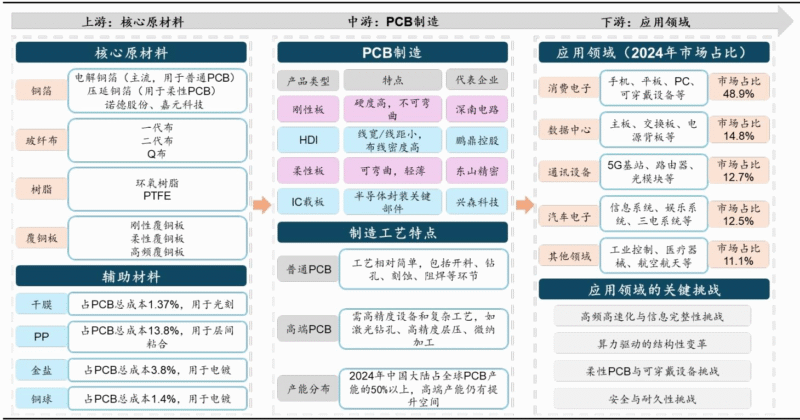
三、关键升级环节:光、液冷、供电、芯片全面迭代
- 光通信:800G/1.6T光模块需求爆发,光芯片供需紧张,核心标的包括中际旭创(1.6T量产)、源杰科技(光芯片突破)。
- 液冷:机柜功耗攀升至132KW,散热从风冷→风液混合(液冷占比80%+)→全液冷,关键部件包括冷板、CDU(冷却分配单元)、快接头UQD,推荐英维克。
- 供电:采用Power shelf供电单元(支持N+2冗余)、Busbar母线减少损耗,适配高功率需求,受益标的包括中恒电气、科华数据。
- 芯片:交换芯片(盛科通信12.8/25.6Tbps产品落地)、AI芯片(昇腾910C双die方案)、CPU(鲲鹏920)成为核心支撑。
四、国产超节点案例:华为Atlas系列引领突破
-
华为Atlas 900 A3(CloudMatrix 384)
- 配置:192颗鲲鹏CPU+384颗昇腾910C,12个计算柜+4个UB交换机柜。
- 性能:BF16 dense PFLOPS达300(NVL72的1.7倍),总内存带宽1229TB/s(NVL72的2.1倍)。
- 部署:累计超300套,服务20+客户。
-
华为Atlas 950/960 SuperCluster
型号 NPU支持数量 FP8算力 互联带宽 上市时间 Atlas 950 8192张 8EFlops 16.3PB/s 2026Q4 Atlas 960 15488张 60EFlops 34PB/s 2027Q4
五、投资建议:三大主线+四大赛道
| 核心主线 | 覆盖领域 | 推荐标的 | 受益标的 |
|---|---|---|---|
| 网络端 | 光模块/光芯片、交换机/芯片 | 中际旭创、新易盛、盛科通信-U | 长光华芯、锐捷网络 |
| AIDC | 液冷、供电、机房 | 英维克、大位科技、光环新网 | 申菱环境、科华数据 |
| 计算端 | AI芯片、服务器、服务器电源 | 中兴通讯、紫光股份、欧陆通 | 寒武纪-U、浪潮信息 |
六、风险提示
- AI发展不及预期:云厂商资本开支放缓,影响超节点产业链需求。
- 芯片供应风险:算力/网络芯片供应短缺,拖累超节点出货节奏。
- 市场竞争加剧:多家企业布局相关产品,盈利能力承压。
4. 关键问题及答案
问题1:超节点的核心价值是什么?其技术实现的核心的是什么?
- 答案:核心价值是破解AI大模型的“通信墙”瓶颈,通过Scale Up纵向扩展将算力芯片整合为“超级GPU”,实现高带宽(如NVL72总带宽130TB/s)、低时延(节点间延迟增加<1微秒)的域内互联,同时结合Scale Out横向扩展,支撑万卡/百万卡级集群,满足万亿参数模型的训练/推理需求;此外,国产超节点可弥补单卡算力差距(如华为CloudMatrix 384 BF16性能是NVL72的1.7倍)。技术实现核心包括两点:①组网拓扑创新,通过胖树(英伟达)、Mesh(华为)、Torus(谷歌)等拓扑实现无阻塞互联;②互联协议升级,从私有(NVLink)到开源(UB/OISA),提升带宽(单卡最高1.8TB/s)、降低时延(数百纳秒级),支持异构算力协同。
问题2:国产超节点(以华为Atlas系列为例)实现了哪些关键突破?相比海外产品有何优势?
- 答案:关键突破:①规模突破,从Atlas 900 A3(384张NPU)迭代至Atlas 960(15488张NPU),支持百万卡级集群;②性能突破,CloudMatrix 384的总内存容量(49.2TB)是NVL72的3.6倍,总内存带宽(1229TB/s)是其2.1倍;③协议自主,基于自研UB协议,实现域内/域间融合组网,节点间带宽衰减<3%。相比海外优势:①开源兼容,UB/OISA协议开放,适配国产AI芯片/服务器,避免生态封闭;②性价比优势,通过架构优化弥补单卡制程差距,集群性能反超(BF16算力1.7倍);③场景适配,支持全液冷、高功率部署(Atlas 950功耗适配559KW),适配国内IDC机房需求。
问题3:超节点产业链的投资主线是什么?各主线的核心逻辑及代表标的有哪些?
- 答案:投资主线聚焦“网络端+AIDC+计算端”三大方向,核心逻辑与代表标的如下:①网络端:核心逻辑是超节点高带宽互联需求拉动光模块、交换芯片升级,代表标的包括中际旭创(1.6T光模块量产)、盛科通信-U(25.6Tbps交换芯片落地);②AIDC端:核心逻辑是机柜功耗攀升(最高132KW)带动液冷、供电、机房升级,代表标的包括英维克(液冷龙头,冷板/CDU全覆盖)、光环新网(超节点机房服务商);③计算端:核心逻辑是超节点对AI芯片、服务器、电源的规模化需求,代表标的包括中兴通讯(自研AI交换芯片+超节点产品)、欧陆通(高功率服务器电源龙头)。
© 版权声明
免费分享是一种美德,知识的价值在于传播;
本站发布的图文只为交流分享,源自网络的图片与文字内容,其版权归原作者及网站所有。
THE END











暂无评论内容