

行业标杆,领先优势建立在NVLink和NVLink Switch
【原报告在线阅读和下载】:20260205【MKList.com】超节点与Scale up网络专题之英伟达:行业标杆,领先优势建立在NVLink和NVLink Switch | 四海读报
【迅雷批量下载】:链接:https://pan.xunlei.com/s/VOXJ23RJHhoECPL5FRrVathfA1 提取码:umqb
【夸克批量下载】:链接:https://pan.quark.cn/s/fe42cc605010 提取码:j4Vv
1. 一段话总结
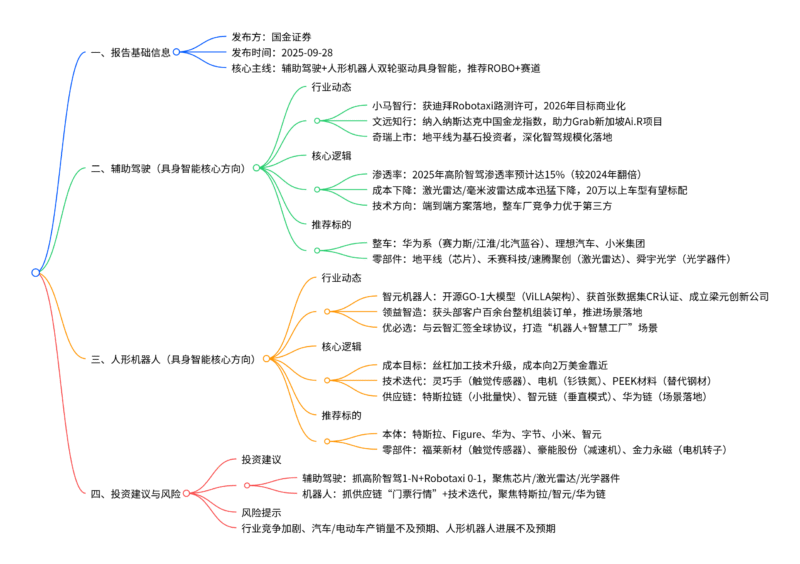
LLM模型从千亿级向万亿级参数演进,张量并行(TP) 与专家并行(EP) 对高带宽(数百至数千GB/s级)、低延迟(百纳秒级)的严苛需求,驱动超节点成为AI算力网络核心创新方向;英伟达凭借自研NVLink与NVLink Switch构建绝对领先优势,已推出GH200 NVL72、GB200 NVL72、VR200 NVL72三代超节点,VR200单GPU互连带宽达3.6TB/s、总交换容量259.2TB/s,未来将迭代至NVL144(144颗GPU)、NVL576(576颗GPU);其优势源于网状拓扑、统一内存等技术创新,建议关注其供应链及国产替代厂商,需警惕技术路径变化、出货不及预期等风险。
2. 思维导图(mindmap)
3. 详细总结
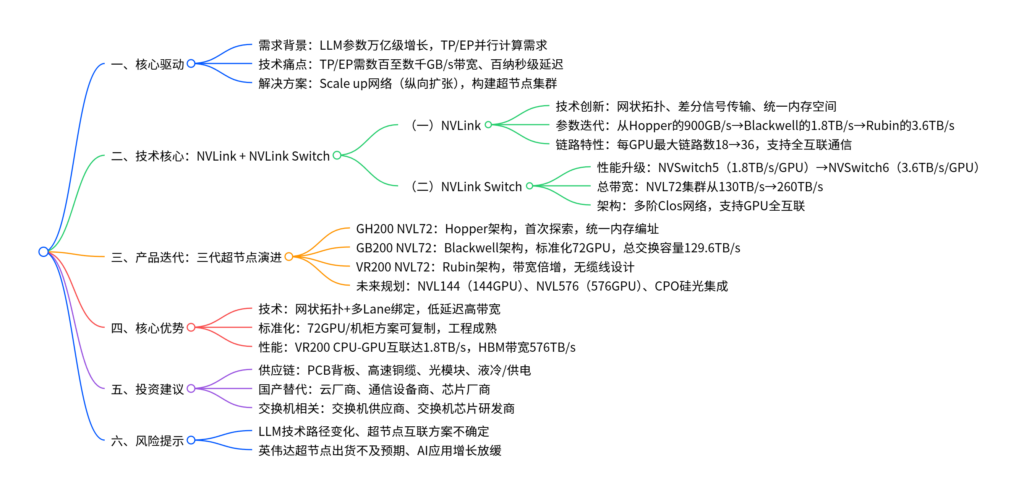
一、超节点兴起的核心驱动
-
LLM并行计算需求倒逼技术升级
- 大语言模型参数从千亿级迈向万亿级,跨服务器张量并行(TP) 与混合专家模型(MoE) 带来的专家并行(EP) 成为必然选择。
- TP/EP对带宽要求达数百至数千GB/s级,延迟要求为百纳秒级,传统网络无法满足,催生Scale up(纵向扩张) 网络架构。
-
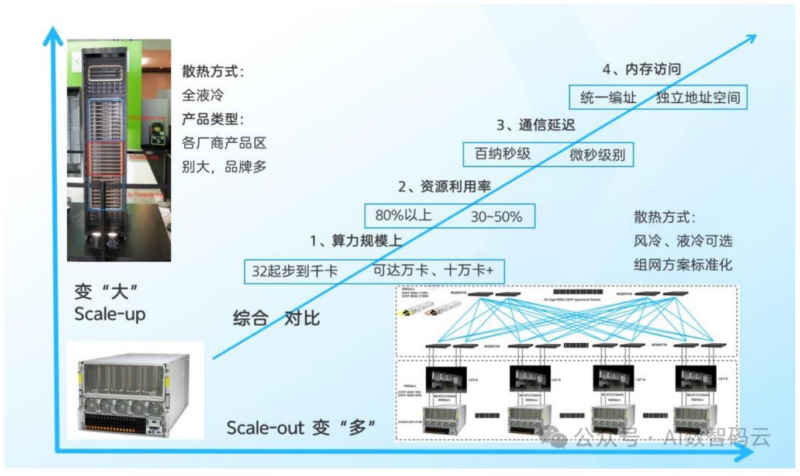
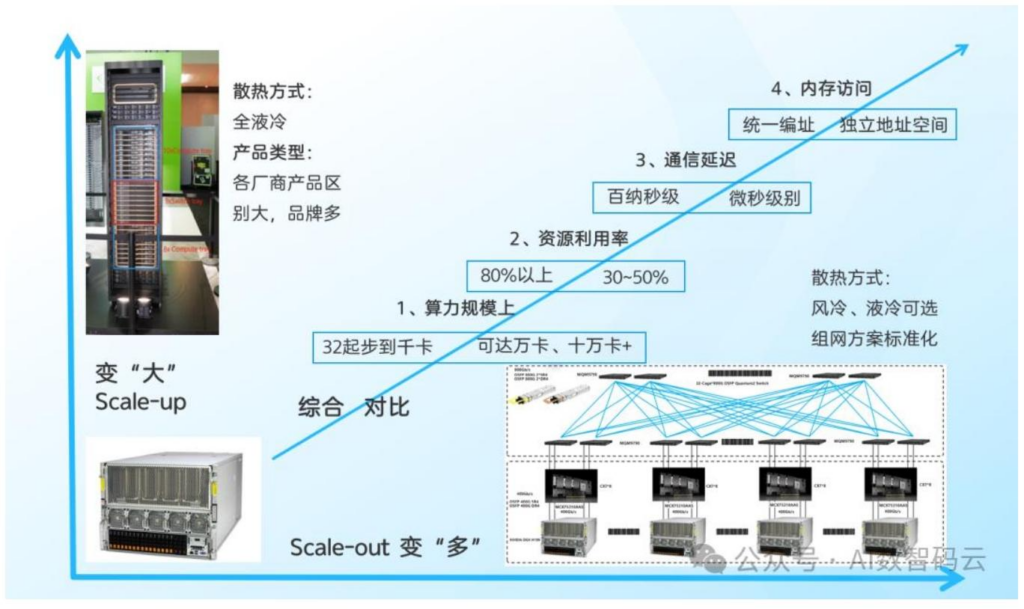
Scale up与Scale out网络对比
对比维度 Scale up(超节点核心) Scale out(传统集群) 算力规模 数十卡至千卡级 万卡至十万卡级 资源利用率 80%以上 30%-50% 通信延迟 百纳秒级 微秒级 内存访问 统一内存/全局地址空间 独立内存空间 标准化程度 定制化程度高 基于开放网络标准 互联方案 铜缆(低功耗低成本)/光纤(大规模) 以太网为主
二、核心技术:NVLink与NVLink Switch的协同创新
-
NVLink:高速互联的核心协议
-
技术创新:采用网状拓扑实现GPU多对多直接通信,差分信号传输提升抗干扰性,通过信用机制实现流量调度,支持多Lane绑定与统一内存空间。
-
参数迭代:
架构 单GPU互连带宽 每GPU最大链路数 支持GPU集群规模 Hopper 900GB/s 18 72颗 Blackwell 1.8TB/s 18 72颗 Rubin 3.6TB/s 36 72/144/576颗
-
-
NVLink Switch:全互联的关键枢纽
-
架构升级:采用多阶Clos网络,解决点对点连接复杂度平方级增长问题,实现任意GPU间无阻塞通信。
-
性能演进:
型号 单GPU-GPU带宽 总聚合带宽(NVL72集群) 支持架构 NVSwitch4 900GB/s 72TB/s Hopper NVSwitch5 1.8TB/s 130TB/s Blackwell NVSwitch6 3.6TB/s 260TB/s Rubin
-
三、英伟达超节点产品迭代路线
| 产品型号 | 架构 | 首发时间 | 核心配置 | 关键性能 | 互联方案 |
|---|---|---|---|---|---|
| GH200 NVL72 | Hopper | 2024年 | 72颗H200 GPU+36颗Grace CPU | 算力180 PFLOPS(TF32),内存带宽576TB/s | 铜缆互联,NVLink4 |
| GB200 NVL72 | Blackwell | 2025年 | 72颗B200 GPU+36颗Grace CPU | 总交换容量129.6TB/s,功耗145KW | 铜缆互联(5184根DAC),NVLink5 |
| VR200 NVL72 | Rubin | 2026年1月 | 72颗VR200 GPU+36颗Vera CPU | 单GPU带宽3.6TB/s,总交换容量259.2TB/s | 铜缆+PCB中板,NVLink6 |
| 未来规划 | – | – | – | – | – |
| Vera Rubin NVL144 | Rubin | 2026下半年 | 144颗VR200 GPU+72颗Vera CPU | CPU-GPU互联1.8TB/s | 铜缆背板+板载无源光引擎 |
| Rubin Ultra NVL576 | Rubin Ultra | 2027年 | 576颗VR300 GPU+288颗Vera Ultra CPU | 单GPU MVFP4 100PFLOPS | 3.2T CPO硅光 |
四、英伟达超节点的核心优势
- 技术壁垒:NVLink的网状拓扑、统一内存等创新,实现低延迟(百纳秒级)、高带宽(NVL72集群260TB/s)的全互联通信。
- 标准化程度:GB200 NVL72将超节点规模稳定为72GPU/机柜,形成可复制方案,2025年出货量预计2800台。
- 工程创新:VR200采用无缆线设计,通过PCB中板替代传统线缆,SerDes速率升级至448G,铜缆用量保持5184根但传输效率翻倍。
五、投资建议与风险提示
-
投资建议
- 英伟达供应链:关注PCB背板、高速铜缆、光模块(CPO方向)、供电与液冷系统等环节。
- 国产替代:关注国内云厂商(阿里/腾讯/百度)、通信设备商(中兴通讯/紫光股份)、芯片厂商(华为/沐曦股份)的超节点布局。
- 交换机相关:聚焦国内交换机供应商及交换机芯片研发商(盛科通信等)。
-
风险提示
- LLM训练与推理技术路径变化,降低TP/EP规模需求;
- 超节点互联方案存在不确定性,光纤替代铜缆可能影响供应链;
- 英伟达超节点出货量低于预期,AI应用端增长不及预期。
4. 关键问题及答案
问题1:英伟达超节点的核心技术优势体现在哪里?其技术创新如何支撑LLM的并行计算需求?
- 答案:核心技术优势集中在NVLink与NVLink Switch的协同创新:①NVLink采用网状拓扑实现GPU多对多直接通信,搭配差分信号传输、多Lane绑定技术,解决传统总线拥堵问题;②NVLink Switch基于多阶Clos网络,支持GPU全互联,避免点对点连接的复杂度激增;③统一内存空间设计,实现GPU与CPU内存统一编址,满足TP/EP的内存共享需求。技术支撑逻辑:TP/EP需数百至数千GB/s带宽与百纳秒级延迟,NVLink 6实现单GPU互连带宽3.6TB/s,NVL72集群总带宽260TB/s,资源利用率超80%,完美匹配并行计算对通信性能的严苛要求。
问题2:英伟达三代超节点(GH200/GB200/VR200)的核心性能与技术差异是什么?未来迭代方向是什么?
- 答案:核心差异集中在带宽、架构与工程设计:①GH200(Hopper):首次探索超节点,单GPU带宽900GB/s,实现内存统一编址;②GB200(Blackwell):标准化72GPU方案,总交换容量129.6TB/s,采用5184根DAC铜缆互联;③VR200(Rubin):单GPU带宽翻倍至3.6TB/s,总交换容量259.2TB/s,无缆线设计+PCB中板,SerDes速率升级至448G。未来迭代方向:2026下半年推出NVL144(144颗GPU),2027年推出NVL576(576颗GPU),引入CPO硅光技术(3.2T/6.4T),通过Kyber机架架构用PCB中板替代5000+根有源铜缆。
问题3:超节点赛道的投资机会集中在哪些方向?国内厂商的核心竞争逻辑是什么?
- 答案:投资机会分为三大方向:①英伟达供应链,受益于其超节点规模化出货,重点关注PCB背板、高速铜缆、CPO光模块、液冷/供电系统;②国产替代,国内厂商通过开放协议(如华为UB、UALink)构建差异化方案,聚焦云厂商的超节点部署与通信设备商的硬件配套;③交换机及芯片,交换机是Scale up网络核心,国内厂商在中低端交换机已实现突破,芯片自研能力是关键竞争力。国内厂商核心竞争逻辑:依托本土化服务与政策支持,在开放协议路线上构建生态,弥补封闭协议(NVLink)的技术差距,聚焦国产AI芯片的超节点适配需求。











暂无评论内容