


【原报告在线阅读和下载】:20260227【MKList.com】电子行业深度报告:端云协同驱动AI入口重塑与硬件范式重构 | 四海读报
【迅雷批量下载】:链接:https://pan.xunlei.com/s/VOXJ23RJHhoECPL5FRrVathfA1 提取码:umqb
【夸克批量下载】:链接:https://pan.quark.cn/s/fe42cc605010 提取码:j4Vv

1. 一段话总结
东吴证券2026年电子行业深度报告指出,端云协同成为AI发展核心范式,驱动AI入口重塑与硬件范式重构:云端大模型沿“低延迟交互+长链推理” 双路径演进,海外OpenAI、Anthropic等强化Code模型与多Agent能力,国内模型呈现“性能追平+价格下探” 特征(如MiniMax M2.5输入价格0.3美元/MTok);端侧模型通过多模态能力升级与算法优化(低比特量化、推理效率提升)适配硬件约束,与云端形成“高频轻量任务本地闭环、重算力任务上云”的分工;硬件端同步升级,LPDDR6内存(能效提升21%)、Exynos 2600芯片(热阻降低16%)等实现算力、存力与散热协同,为端侧AI多模态化、复杂化提供支撑。
2. 思维导图(mindmap脑图)
3. 详细总结
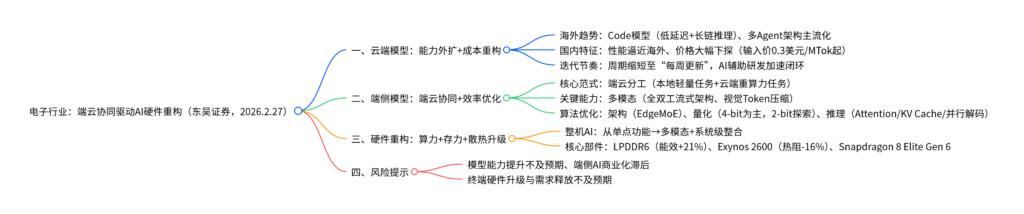
一、云端模型:能力边界外扩与成本重构并行
云端大模型作为端侧AI的技术源头,2026年进入以“任务完成能力”为核心的迭代期,海外引领技术方向,国内凸显性价比优势。
1. 海外:大模型加速迭代,Agent能力持续突破
-
核心演进方向:
- Code模型双路径:① 低延迟交互(OpenAI GPT-5.3-Codex):响应速度超1000 Tokens/秒,支持实时打断纠偏,适配个人高频生产场景;② 长链推理(Claude Opus 4.6):1M Token上下文窗口,适配金融、法律等B端复杂任务。
- 多Agent架构主流化:Grok 4.20推出4个分工明确的专家Agent,通过内部辩论机制使幻觉率下降65%(MMLU-Pro达95%),推理成本仅为单模型的1.5-2.5倍,OpenAI等确认将跟进该架构。
-
迭代节奏:模型更新周期从6-12个月缩短至“每周更新”,AI辅助AI研发形成闭环,系统性压缩开发周期。
2. 国内:性能追平+价格下探,需求加速释放
-
供给端特征:
- 性能逼近海外:智谱GLM-5、字节豆包2.0等在综合推理、多模态能力上对标海外头部模型,阿里Qwen 3.5计算机控制能力对齐国际顶尖水平。
- 价格大幅下探:国产模型性价比优势显著,具体价格对比如下:
| 模型类型 | 代表模型 | 上下文窗口 | 输入价格(美元/MTok) | 输出价格(美元/MTok) |
|---|---|---|---|---|
| 国产模型 | MiniMax M2.5 | 1M | 0.3 | 1.2 |
| GLM-5 | 200K | 1.0 | 3.2 | |
| 海外模型 | GPT-5 | 400K | 1.25 | 10.0 |
| Claude Opus 4.5 | – | 5.0 | 25.0 |
- 需求端变化:MiniMax M2.5上线24小时内生成1万个“专家Agent”,智谱GLM-5因需求强劲上调定价30%,字节Seedance 2.0激活短视频与二创生态,显示需求弹性持续释放。
二、端侧模型:端云协同主线下的效率优化与能力压缩
端侧模型的核心逻辑是与云端分工协同,而非替代,通过多模态升级与算法优化适配硬件约束。
1. 核心范式:端云协同成主流
- 分工架构:① 端侧:处理高频、轻量、强隐私任务(实时感知、本地决策),形成本地闭环;② 云端:处理重推理、长生成、高算力任务(复杂计算、长文本处理)。
- 典型案例:Google FunctionGemma(270M参数),可将自然语言翻译为API操作,作为独立智能体处理离线任务,或作为分流器调度复杂任务至云端模型。
2. 关键能力:多模态成竞争核心
-
核心优势:端侧天然适配多模态“零延迟”交互,规避云端网络时延问题。
-
技术方向:
- 全双工流式架构:MiniCPM-o 4.5、Qwen2.5-Omni支持音视频输入与文本/语音输出的非阻塞处理,弱化“回合制问答”。
- 视觉Token压缩:MiniCPM-V 4.5通过3D-Resampler技术压缩高分辨率视频Token,突破端侧带宽与算力瓶颈。
3. 算法优化:效率与能力的平衡
- 模型架构:MoE受限于端侧内存瓶颈,EdgeMoE通过分区存储专家权重,提升1.2-2.7倍推理性能;同时探索Gated DeltaNet、混合架构等替代方案。
- 低比特量化:4-bit为行业标准(压缩4倍显存,精度衰减1%-3%),2-bit及以下量化需从头训练,Microsoft BitNet验证1.58-bit可行性。
| 量化位宽 | 压缩比 | 精度衰减 | 核心场景 |
|---|---|---|---|
| 8-bit | 2x | 几乎无损 | 云端/服务端 |
| 4-bit | 4x | 1%-3% | 云端/移动端/边缘端 |
| <4-bit | 4x-8x | ~3% | 移动端/边缘端(受限硬件) |
| 向量量化 | 8x | ~3% | 专用硬件加速器(如苹果NE) |
-
推理优化:
- Attention效率:FlashAttention系列提升FLOPs利用率,端侧采用local-global attention等适配缓存。
- KV Cache管理:StreamingLLM、ChunkKV等技术压缩缓存至3bit,吞吐提升26%。
- 并行解码:Medusa、EAGLE实现2.2-3.6倍加速,Diffusion LLM结合并行解码可提速4-6倍。
三、端侧模型牵引硬件重构:算力、存力与散热协同升级
整机AI向多模态与系统级整合演进,倒逼核心硬件围绕内存、算力、散热同步升级。
1. 整机AI功能演进
- 2024年:聚焦高频刚需场景(图像消除、文本摘要);
- 2025年:向多模态创作(语音、生成式图像)延伸,渗透操作系统底层;
- 竞争焦点:从功能数量转向多模态体验与系统级整合深度。
2. 核心硬件升级
- 存储端:三星LPDDR6内存,数据传输速率10.7 Gbps,通过动态电压调节与智能PMIC管理,能效提升21%,适配AI负载波动。
- 算力端:三星Exynos 2600芯片引入High-k EMC材料,热阻降低16%,缓解重载场景降频问题;高通Snapdragon 8 Elite Gen 6 Pro版将支持LPDDR6,频率达5-5.5GHz。
- 散热端:高通计划为旗舰芯片配备三星HPB高性能散热方案,保障AI推理等重载场景持续性能。
4. 关键问题
问题1(端云协同):端云协同的核心分工逻辑是什么?这种分工对端侧模型与云端模型的能力演进分别提出了哪些不同要求?
答案:
- 核心分工逻辑:基于任务属性实现高效协同——端侧模型聚焦高频、轻量、强隐私、低延迟任务(如实时感知、本地决策、简单交互),形成本地闭环;云端模型承接重推理、长生成、高算力、复杂场景任务(如长文本处理、大规模代码生成、复杂数据分析),提供强算力支撑,两者通过任务调度实现效率最大化。
- 能力演进要求:① 端侧模型:需强化多模态实时交互能力(适配物理世界感知)、算法压缩能力(低比特量化、推理优化),在有限内存/功耗约束下保障核心功能;② 云端模型:需突破长链复杂推理(大上下文窗口)、低延迟响应双能力,同时通过多Agent架构提升复杂任务完成率,配合端侧需求优化成本与调用效率。
问题2(技术迭代):国内与海外大模型的迭代差异主要体现在哪里?国内模型的性价比优势对行业发展产生了哪些实质性影响?
答案:
- 迭代差异:① 技术方向:海外主导前沿架构探索(Code模型双路径、多Agent),定义行业演进方向;国内聚焦“性能追平+成本优化”,在对齐海外能力的同时大幅降低调用价格;② 迭代节奏:海外以“功能创新”为核心,国内以“需求落地”为导向,价格下探速度更快;③ 生态侧重:海外侧重C端与开发者生态,国内兼顾B端行业应用与C端消费场景。
- 实质性影响:① 激活需求:低价格使多Agent长期部署、高调用量场景具备经济可行性,推动AI应用从PoC向规模化落地过渡;② 降低门槛:吸引中小开发者与中小企业参与,丰富AI原生应用生态;③ 倒逼竞争:海外模型面临价格压力,加速技术下放与成本优化,推动全行业推理成本下降;④ 端侧外溢:性价比优势带动模型向端侧渗透,加速端云协同落地。
问题3(硬件重构):端侧AI能力升级对核心硬件(存储、算力、散热)提出了哪些具体要求?当前硬件升级已取得哪些关键突破?
答案:
- 具体要求:① 存储:需提升数据传输速率、内存带宽与能效比,适配多模态数据处理与AI负载波动;② 算力:需平衡性能与功耗,支撑端侧多模态推理、低延迟响应;③ 散热:需优化热传输路径,缓解重载场景(如AI推理)的发热降频问题,保障持续性能。
- 关键突破:① 存储:三星LPDDR6内存传输速率达10.7 Gbps,能效提升21%,支持动态电压调节与智能电源管理;② 算力与散热:三星Exynos 2600芯片引入High-k EMC材料,热阻降低16%;高通Snapdragon 8 Elite Gen 6 Pro版将支持LPDDR6,搭配HPB高性能散热方案,实现算力与散热协同升级;③ 整体架构:硬件从单点升级转向“算力-存力-散热”协同优化,适配端侧AI多模态、复杂化发展趋势。











暂无评论内容