


2014年,伊恩·古德费洛(lanGoodfellow)提出的生成对抗网络(GenerativeAdversarialNetwork,GAN)成为早期最为著名的生成模型。GAN使用合作的零和博弈框架来学习,被广泛用于生成图像、视频、语音和三维物体模型。随后,Transformer、基于流的生成模型(Flow-basedmodels)、扩散模型(DiffusionModel)等深度学习的生成算法相继涌现。
2017年,Google颠覆性地提出了基于自注意力机制的神经网络结构——Transformer架构,奠定了大模型预训练算法架构的基础。
2018年,OpenAI和Google分别发布了GPT-1与BERT大模型,意味着预训练大模型成为自然语言处理领域的主流。
通过梳理全球主流大语言模型(LLM)的发展脉络,2018年以来的GPT系列、LLaMA系列、BERT系列、Claude系列等多款大模型均发源于Transformer架构。
免费资源
© 版权声明
免费分享是一种美德,知识的价值在于传播;
本站发布的图文只为交流分享,源自网络的图片与文字内容,其版权归原作者及网站所有。
THE END






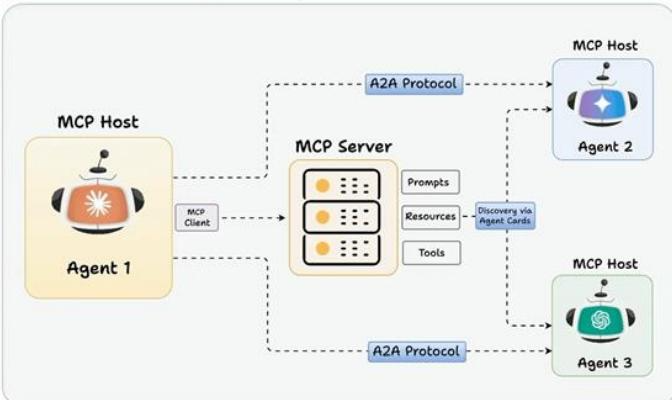







暂无评论内容