

DeepSeek的稀疏注意力机制给AI产业释放更大的发展潜能
【原报告在线阅读和下载】:20251016【MKList.com】人工智能专题:DeepSeek的稀疏注意力机制给AI产业释放更大的发展潜能 | 四海读报
【迅雷批量下载】:链接:https://pan.xunlei.com/s/VOXJ23RJHhoECPL5FRrVathfA1 提取码:umqb
【夸克批量下载】:链接:https://pan.quark.cn/s/fe42cc605010 提取码:j4Vv
1. 一段话总结
本报告(中原证券2025年10月16日发布,行业评级强于大市)指出,注意力机制是大模型处理长文本的核心,但面临显存开销与计算复杂度瓶颈;DeepSeek作为开源大模型代表,通过三次关键技术改进突破瓶颈:①MLA(多头潜在注意力) 减少90%注意力分数显存占用,降低42.5%训练成本;②NSA(原生稀疏注意力) 实现算法与硬件协同优化,长文本处理速度提升11倍,上下文可拓展至百万tokens;③DSA(DeepSeek稀疏注意力) 基于既有模型升级,无需重新训练,使模型API调用价大幅下降(输入缓存命中价仅0.2元/百万Tokens,为R1的20%);稀疏注意力将计算复杂度从O(L²) 降至亚平方级,推动大模型从“预训练Scaling”转向“后训练提效”,为AI产业释放更大发展潜能,同时提示国际形势不确定性风险。
2. 思维导图(mindmap)

3. 详细总结
一、报告基础信息
| 项目 | 内容 |
|---|---|
| 报告类型 | 人工智能行业专题报告(DeepSeek稀疏注意力机制) |
| 发布机构 | 中原证券 |
| 发布日期 | 2025年10月16日 |
| 行业评级 | 强于大市(维持) |
| 核心分析师 | 唐月(S0730512030001) |
| 核心逻辑 | DeepSeek的稀疏注意力机制(NSA/DSA)突破大模型显存与算力瓶颈,推动后训练提效,释放AI产业潜能 |
二、注意力机制与大模型发展的关系
- 注意力机制的核心价值
人类通过选择性关注关键信息提升处理效率,深度学习模仿这一能力引入注意力机制,2017年谷歌《Attention Is All You Need》确立Transformer架构,解决了传统RNN的长序列遗忘问题,使大模型上下文长度从早期提升至128K甚至1M tokens。 - 大模型发展的核心瓶颈
传统稠密注意力机制的计算复杂度为O(L²)(L为序列长度),随文本长度增加,显存开销与计算成本呈平方级增长,限制长文本处理能力与模型Scaling(规模扩张)。 - 突破路径
行业通过算法、系统、硬件三层面优化突破瓶颈,其中算法层面的稀疏注意力是关键——将计算复杂度降至亚平方级(如O(LlogL)、O(L*k)),仅对部分关键信息进行注意力计算,兼顾效率与性能。
三、DeepSeek在注意力机制的三次关键技术改进
DeepSeek作为开源大模型与低成本模型标杆,通过三次技术迭代优化注意力机制,具体如下表:
| 技术名称 | 发布时间 | 核心改进 | 关键效果 | 技术细节 |
|---|---|---|---|---|
| MLA(多头潜在注意力) | 2024年5月(V2模型) | 引入低秩近似压缩KV Cache | 1. 注意力分数显存占用减少90%; 2. 训练成本降低42.5%; 3. 生成吞吐量提升576% |
改进传统MHA(多头注意力),通过潜在空间压缩键值缓存,成为R1模型成本低的核心原因 |
| NSA(原生稀疏注意力) | 2025年2月(论文发布) | 算法与硬件协同优化 | 1. 长文本处理速度提升11倍; 2. 性能比肩稠密注意力; 3. 上下文可拓展至百万tokens |
1. 以“块”为粒度挑重点,解决GPU稀疏计算适配难题; 2. 首次在预训练阶段引入稀疏注意力,避免训练-推理误差; 3. 获ACL 2025最佳论文 |
| DSA(DeepSeek稀疏注意力) | 2025年9月(V3.2-Exp) | 基于既有模型升级,无需重训 | 1. API调用价大幅下降(输入缓存命中0.2元/百万Tokens,为R1的20%); 2. 发布当日适配寒武纪/华为昇腾 |
1. 用“闪电索引器”筛选2048个关键词汇,细粒度稀疏计算; 2. 基于TileLang框架(优于Triton),适配国产芯片; 3. 低成本探索稀疏注意力,无需重新训练基座模型 |
四、DSA与NSA的核心差异
| 对比维度 | NSA(原生稀疏注意力) | DSA(DeepSeek稀疏注意力) |
|---|---|---|
| 实现方式 | 参与完整预训练过程,从基座模型开始构建 | 基于既有模型(V3.1-Terminus)升级,仅需补充训练 |
| 编程框架 | 采用OpenAI开源的Triton框架 | 采用TileLang框架,支持更多深度优化,适配国产芯片 |
| 稀疏逻辑 | 分三层以“块”为粒度挑重点 | 用“闪电索引器”逐词筛选2048个关键词汇 |
| 核心优势 | 性能稳定,上下文拓展能力强(百万tokens) | 成本低(无需重训),适配性好(国产芯片) |
| 适用场景 | 长文本处理(如百万tokens文档分析) | 低成本稀疏注意力验证、国产芯片生态场景 |
五、稀疏注意力对AI产业的价值:释放后训练潜能
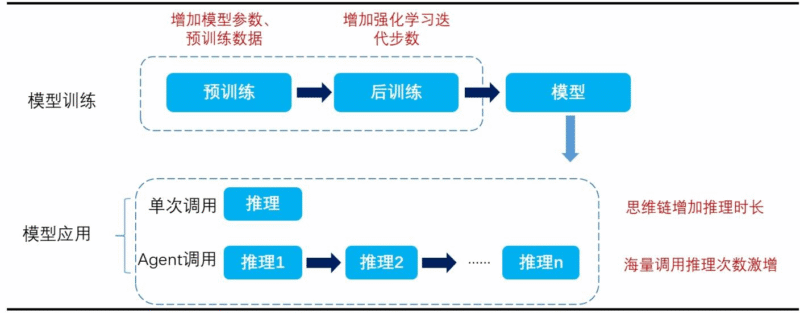
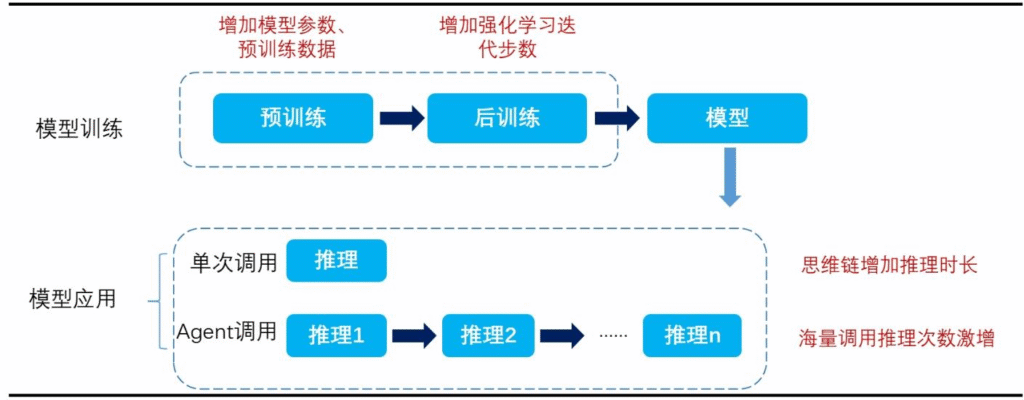
- 推动模型Scaling新范式
传统Scaling依赖预训练阶段“增参数、增数据”,面临成本瓶颈;稀疏注意力使大模型转向后训练提效——通过增加强化学习迭代步数(而非增大模型规模)提升能力。例如DeepSeek-R1-Zero在训练中,随强化学习步数增加,AIME精度持续提升,响应时长适配长思维链需求。 - 降低应用端门槛
DSA带来的模型降价(输入缓存命中价0.2元/百万Tokens)提升性价比,促进AI应用落地(如长文本对话、多模态生成),推动更多功能从“技术验证”转向“商业化推广”。 - 支撑国产芯片生态
DSA基于TileLang框架,可深度适配寒武纪、华为昇腾等国产芯片,解决稀疏计算在国产硬件上的效率问题,推动“算法-硬件”协同国产化。
六、风险提示
- 国际形势不确定性:全球AI技术竞争、供应链限制可能影响稀疏注意力技术的跨境合作与硬件适配。
4. 关键问题
问题1:DeepSeek的NSA(原生稀疏注意力)为何能成为ACL 2025最佳论文?其在技术上的突破性创新体现在哪些方面?
答案:
NSA成为ACL最佳论文的核心原因是其首次实现“预训练阶段原生稀疏注意力”,解决了行业长期存在的“训练-推理不一致”问题,同时兼顾性能与效率。技术突破性创新体现在三方面:
- 训练阶段稀疏化:此前稀疏注意力仅应用于推理阶段,预训练仍用稠密注意力,导致训练与推理存在误差;NSA首次在预训练阶段引入稀疏注意力,性能比肩甚至超越稠密注意力(在通用基准、长上下文任务、推理任务上平均表现更优)。
- 软硬协同优化:针对GPU不适合稀疏计算的难题,NSA以“块”为粒度设计注意力结构,同时引入丰富算子优化硬件适配,使64K序列处理速度在解码、前向传播、反向传播阶段均提升11倍,突破显存与算力瓶颈。
- 上下文拓展能力:NSA支持将模型上下文拓展至百万tokens,远超传统模型(如128K),为长文本分析(如百万字文档总结)提供技术支撑,打开新应用场景。
问题2:DSA(DeepSeek稀疏注意力)相比NSA,在商业化落地层面具备哪些优势?这些优势如何推动AI应用普及?
答案:
DSA在商业化落地层面的核心优势是“低成本、高适配性”,具体推动AI应用普及的逻辑如下:
- 无需重新训练,降低研发成本:DSA基于既有模型(V3.1-Terminus)升级,无需从零开始预训练基座模型,大幅减少研发时间与算力投入(节省超50%训练成本),使中小企业也能低成本探索稀疏注意力,加速技术普及。
- 价格大幅下降,降低应用门槛:DSA使模型API调用价显著降低——输入缓存命中时0.2元/百万Tokens(为R1的20%)、输出3元/百万Tokens(为R1的19%),性价比提升推动应用端(如客服、文档处理)扩大使用规模,实现“降本→放量→再降本”的商业飞轮。
- 适配国产芯片,拓展落地场景:DSA基于TileLang框架(优于Triton),发布当日即适配寒武纪、华为昇腾等国产芯片,解决稀疏计算在国产硬件上的效率问题,助力“AI+国产硬件”生态落地,覆盖政府、国企等对国产化要求高的场景。
问题3:稀疏注意力机制(NSA/DSA)如何推动大模型从“预训练Scaling”转向“后训练提效”?这一范式转变对AI产业的长期影响是什么?
答案:
1. 推动范式转变的核心逻辑:
传统“预训练Scaling”依赖增大模型参数(如从67B→6710B)、增加训练数据,导致计算成本呈指数级增长(如训练一次千亿参数模型需数亿美元),面临边际效益递减;稀疏注意力通过两方面支撑“后训练提效”:
- 效率提升:将计算复杂度从O(L²)降至亚平方级,使模型在不增大参数的情况下,能处理更长输入(如百万tokens)、输出更长思维链(如长文本推理),为后训练(如强化学习、指令微调)提供效率支撑;
- 成本可控:DSA等技术降低模型调用与训练成本,使企业可通过“增加后训练迭代步数”(而非增参数)提升模型能力(如DeepSeek-R1-Zero通过更多强化学习步数,AIME精度持续提升),实现“低成本提效”。
2. 对AI产业的长期影响:
- 技术层面:推动行业从“拼参数规模”转向“拼算法效率”,促进稀疏注意力、强化学习等技术创新,形成“效率驱动”的技术竞争格局;
- 商业层面:降低大模型研发与应用成本,使AI从“头部企业专属”转向“中小企业可及”,催生更多垂直场景应用(如行业定制化模型);
- 生态层面:适配国产芯片的特性推动“算法-硬件”协同国产化,减少对海外GPU的依赖,构建自主可控的AI产业生态。










暂无评论内容