

【原报告在线阅读和下载】:20260522【MKList.com】超节点行业:从计算托盘角度拆解英伟达VR NVL72,通信速率三重升级,超级网卡价值显著提升 | 四海读报
【迅雷&夸克批量下载】:四海读报网研究报告网盘批量下载-资源清单社区-认知清单-四海清单
1. 一段话总结
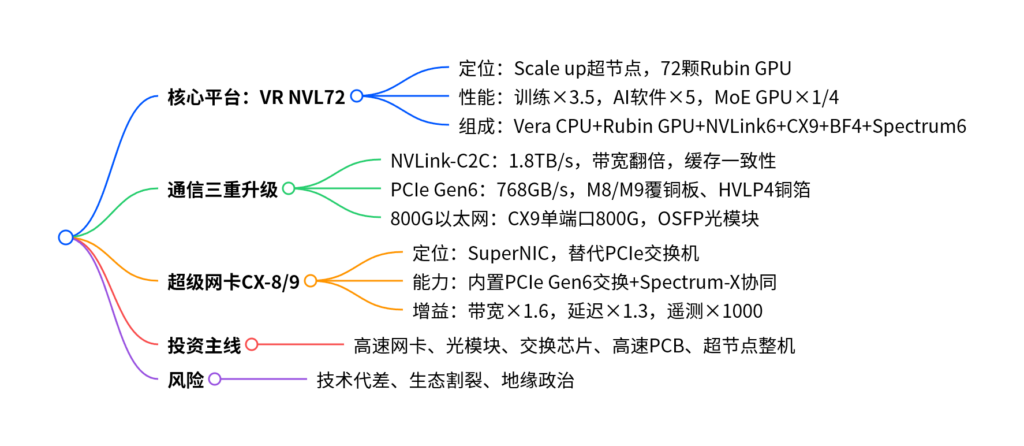
英伟达Vera-Rubin NVL72是全球领先的Scale up架构AI超节点平台,通过NVLink-C2C 1.8TB/s、PCIe Gen6 768GB/s、800G以太网实现通信速率三重升级,ConnectX-9超级网卡集成PCIe交换与Spectrum-X交换逻辑成为核心枢纽,平台训练性能达前代3.5倍、AI软件性能提升5倍、MoE模型训练GPU用量降至1/4;国内在高速互联、超级网卡、高速PCB等领域存在技术代差,五大国产替代主线具备显著投资价值。
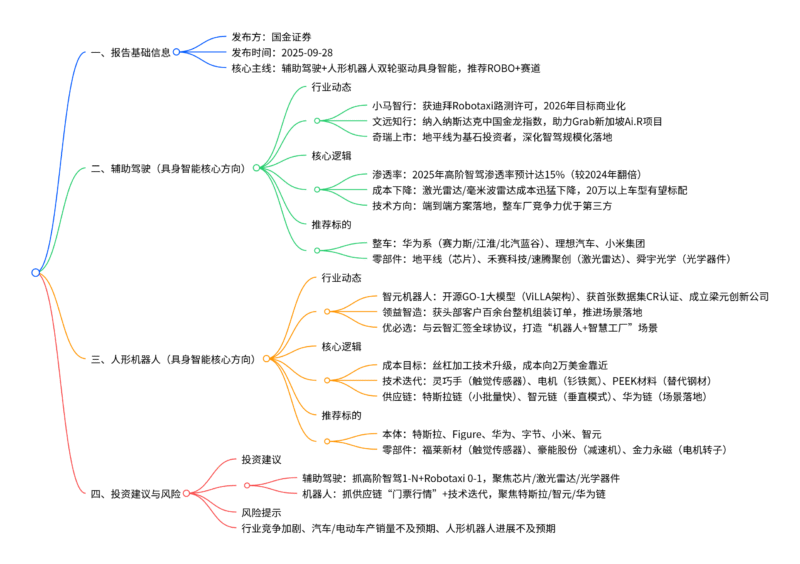
2. 思维导图
3. 详细总结
一、VR NVL72:全球顶尖Scale up AI超节点平台
1. 核心定位与性能
-
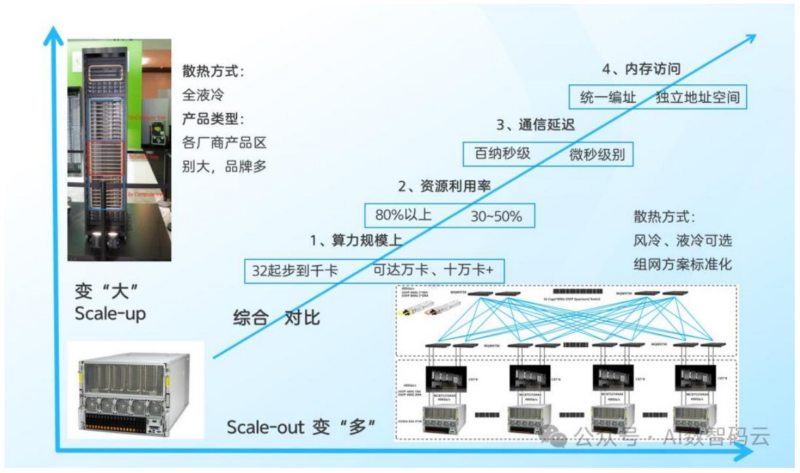
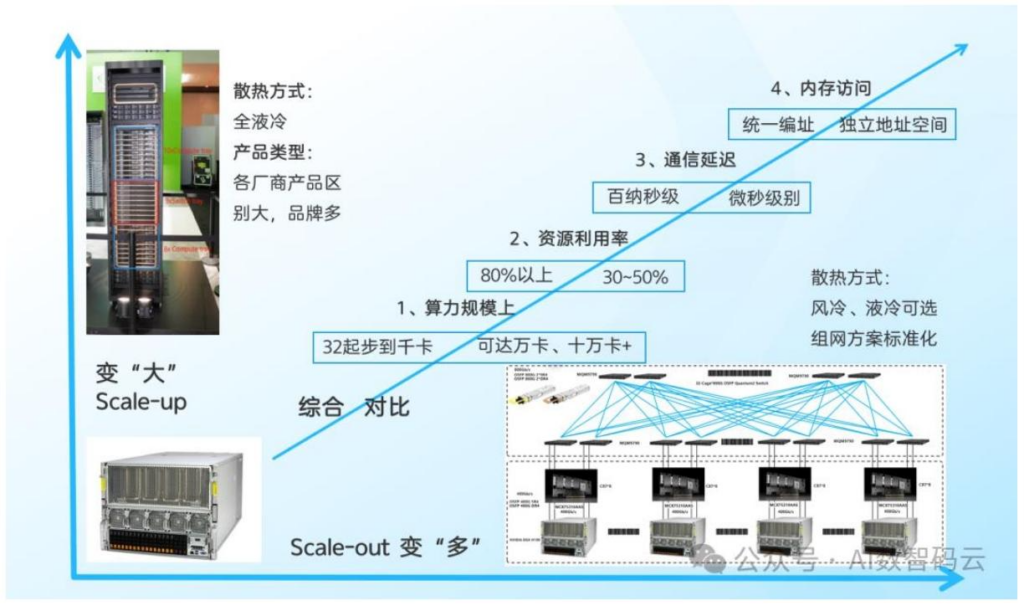
架构类型:Scale up高密度算力集群(区别于Scale out分布式),资源利用率80%+,延迟百纳秒级。
-
硬件组成:6款全新芯片(Vera CPU、Rubin GPU、NVLink 6、ConnectX-9、BlueField-4、Spectrum-6)。
-
性能提升:
- 训练性能:前代Blackwell的3.5倍
- AI软件性能:提升5倍
- MoE模型训练:GPU数量减少至1/4
2. 机柜配置
- 计算托盘:18个,每托盘2×Vera CPU+4×Rubin GPU
- 交换托盘:9个,每托盘4×NVSwitch 6
- 总规模:72颗Rubin GPU、36颗Vera CPU、36颗NVLink 6
二、通信速率三重核心升级(关键数据)
| 通信层级 | 技术方案 | 核心带宽 | 对比前代/行业 | 材料/硬件升级 |
|---|---|---|---|---|
| CPU-GPU互联 | NVLink-C2C | 双向1.8TB/s | GB200(900GB/s)×2;PCIe Gen5(128GB/s)×14 | 硬件缓存一致性,统一内存池 |
| CPU-网卡互联 | PCIe Gen6 | 双向768GB/s | 48 Lane×64Gbps | CCL:M7→M8/M9;铜箔→HVLP4;石英材料 |
| 网卡-外部互联 | 800G以太网/IB | 单端口800G | CX-8以太网仅2×400G | 1.6T/800G OSFP光模块 |
1. NVLink-C2C:芯片间互联革命
- 实现硬件级缓存一致性,CPU与GPU内存统一寻址。
- 延迟降至纳秒级,消除计算等待瓶颈。
2. PCIe Gen6:高速总线换代
- 传输距离达500mm,对PCB与材料提出极高要求。
- 覆铜板、铜箔、玻纤布全面升级,价值量显著提升。
3. 800G以太网:外部互联迈入新时代
- ConnectX-9支持单端口800G以太网,无需链路聚合。
- 光模块方案:4×1.6T OSFP 或 8×800G OSFP。
三、ConnectX超级网卡:价值大幅提升
1. 产品定位:SuperNIC(超级网卡)
- ConnectX-8:单端口800G IB,双端口400G以太网。
- ConnectX-9:单端口800G以太网,实现重大突破。
2. 核心能力
- 内置PCIe Gen6 48通道交换模块,替代独立交换机。
- 集成Spectrum-X交换逻辑,与交换机端到端协同。
- 为GPU提供50GB/s IO带宽,NCCL直接转发流量。
3. 性能增益(端到端优化)
- 有效带宽:×1.6
- 集合通信带宽:×1.3
- All-reduce带宽:×2.2
- All-to-all带宽:×1.3
- 遥测采集速度:×1000
四、投资策略:五大国产替代主线
- 高速网卡:裕太微、盛科通信
- 高端光模块:中际旭创、新易盛、天孚通信
- 高速交换芯片:盛科通信、紫光股份、锐捷网络
- 高速PCB/覆铜板:胜宏科技、生益科技、深南电路
- 国产超节点整机:浪潮信息、中科曙光、工业富联
五、风险提示
- 技术代差:与英伟达存在全栈差距。
- 生态割裂:国产超节点生态协同不足。
- 地缘政治:供应链与技术受限风险。
4. 关键问题
问题1:英伟达VR NVL72的“通信三重升级”分别是什么,核心带宽指标有多大?
答案:三重升级分别是:
- NVLink-C2C:CPU-GPU互联,双向带宽1.8TB/s,较GB200提升1倍;
- PCIe Gen6:CPU-网卡互联,双向带宽768GB/s;
- 800G以太网:网卡-外部互联,单端口800G。
三大环节全面重构AI算力内部与外部通信体系。
问题2:ConnectX-9超级网卡相比传统网卡,核心创新点与价值体现在哪里?
答案:核心创新有两点:
- 内置PCIe Gen6交换模块,替代独立PCIe交换机,消除IO瓶颈;
- 集成Spectrum-X交换逻辑,与交换机端到端协同,使有效带宽提升1.6倍、遥测速度提升1000倍。
它从单纯“接口卡”升级为连接GPU集群的核心ASIC枢纽,价值量大幅提升。
问题3:为何Scale up架构成为AI大模型训练的主流方向,与Scale out有何关键差异?
答案:大模型训练需要极高带宽、极低延迟、强同步,Scale up更适配:
- Scale up:数十至千卡级,利用率80%+,延迟百纳秒级,统一内存,定制化;
- Scale out:万卡级,利用率30%-50%,延迟微秒级,独立内存,标准化。
Scale up能解决大模型训练中“通信等待吞噬算力”的痛点,因此成为VR NVL72这类高端训练平台的首选架构。
© 版权声明
免费分享是一种美德,知识的价值在于传播;
本站发布的图文只为交流分享,源自网络的图片与文字内容,其版权归原作者及网站所有。
THE END











暂无评论内容