

【原报告在线阅读和下载】:20260414【MKList.com】电子行业深度报告:超节点系列报告二:海光&曙光系超节点,HSL+IB构建最全互连体系 | 四海读报
【迅雷批量下载】:链接:https://pan.xunlei.com/s/VOXJ23RJHhoECPL5FRrVathfA1 提取码:umqb
【夸克批量下载】:链接:https://pan.quark.cn/s/fe42cc605010 提取码:j4Vv
一、一段话总结
本报告为东吴证券2026年4月14日发布的电子行业深度报告,核心阐述中科曙光与海光信息保持独立主体下深度战略协同,打造HSL+IB+scaleFabric全栈互连体系,推出scaleX640、scaleX40两款全球领先超节点产品,构建“芯片设计+系统集成”国产智算完整链条,填补国内高速互连网络空白,重点推荐海光信息、中科曙光,并提示AI应用、技术落地、市场竞争三大风险。
二、思维导图
三、详细总结
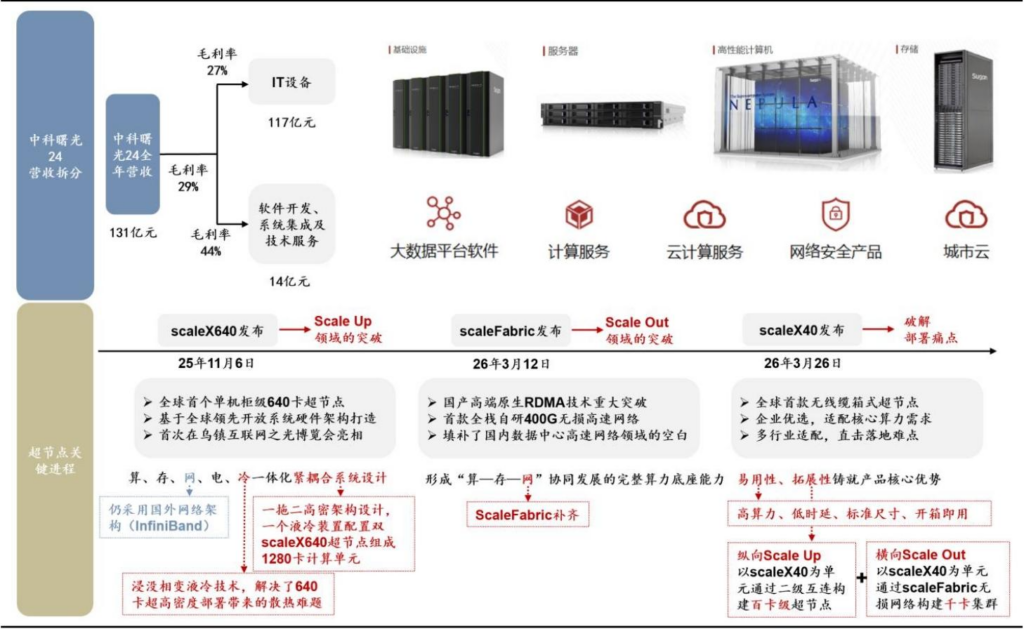
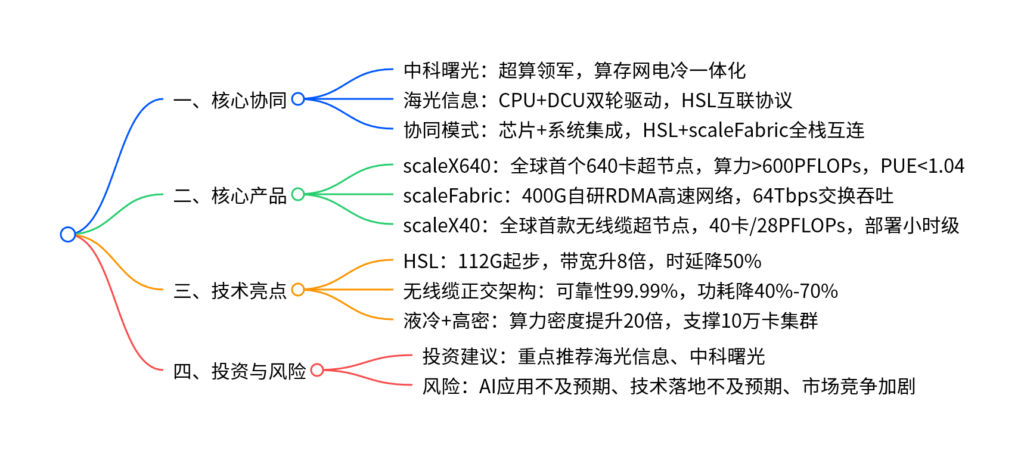
(一)海光&曙光:战略协同打造国产智算全链条
中科曙光与海光信息在保持上市公司独立前提下,形成芯片设计+系统集成完整技术闭环:
-
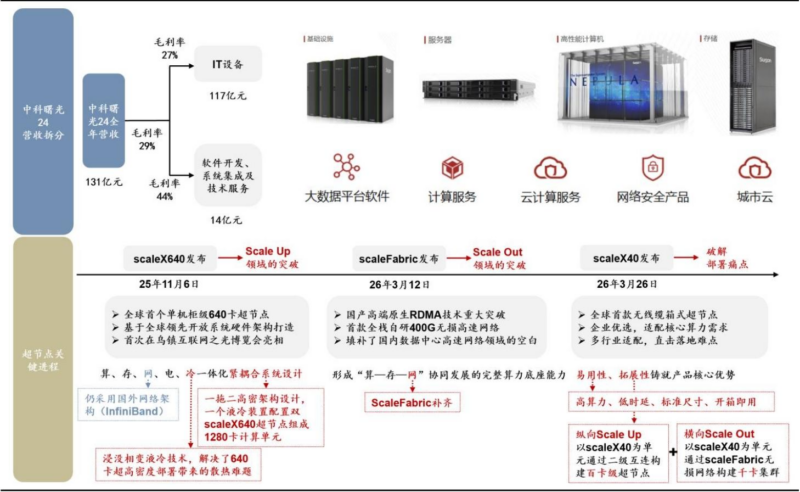
中科曙光
- 超算起家30年,核心信息基础设施龙头,2024年IT设备营收117亿元、软件开发及系统集成14亿元。
- 具备算、存、网、电、冷一体化能力,实现Scale Up(纵向扩展)与Scale Out(横向扩展)双技术突破。
-
海光信息
- 国产高端处理器龙头,CPU+DCU双产品线驱动,CPU兼容x86指令集,已迭代至五号;DCU深算系列迭代至四号,性能对标国际主流GPU。
- 2025年推出HSL(海光系统总线互联协议),起步速率112G,带宽较PCIe提升8倍,时延降低约50%,联合10余家厂商构建生态。
(二)三大核心产品与技术参数
1. scaleX640:全球首个单机柜级640卡超节点
| 核心维度 | 关键参数 |
|---|---|
| 架构 | “一拖二”高密一体化,双节点组成1280卡计算单元 |
| 总算力 | >600PFLOPs |
| 算力密度 | 较同类最大提升20倍 |
| 能效 | PUE<1.04 |
| 兼容性 | 兼容多品牌国产加速卡,支持400+主流大模型 |
| 扩展性 | 支撑10万卡级超大规模AI集群 |
核心优势:超高速正交架构+浸没相变液冷,大模型训推性能提升30%-40%,100+项RAS设计保障稳定。
2. scaleFabric:全栈自研400G无损高速网络
- 国内首款基于RDMA架构的400G高速网络,填补数据中心高速互连空白。
- 物理层:自研112G SerDes IP;芯片层:交换芯片64Tbps双向吞吐,网卡端到端时延<1us。
- 硬件层:1U液冷/2U风冷交换机+400G网卡;软件层:统一架构+集中管理平台,支撑大模型训练、科学计算。
3. scaleX40:全球首款无线缆箱式超节点
| 核心维度 | 关键参数 |
|---|---|
| 架构 | 正交无线缆一级互连,19英寸标准箱式 |
| 算力配置 | 单节点40张GPU,FP8精度>28PFLOPS |
| 部署周期 | 数月→数小时 |
| 可靠性 | 99.99% |
| 扩展性 | 纵向Scale Up百卡级,横向Scale Out千卡级 |
核心优势:消除线缆损耗与运维风险,功耗降低40%-70%,开箱即用,推动算力产品化供给。
(三)投资建议与风险提示
-
投资建议:重点推荐海光信息、中科曙光。
-
风险提示
- AI应用进展不及预期,算力需求释放放缓。
- 核心技术性能、稳定性、生态成熟度不及预期。
- 国内外厂商竞争加剧,价格与份额压力提升。
四、关键问题与答案
问题1:海光与曙光的核心协同价值是什么?HSL协议的核心优势体现在哪里?
答案:协同价值在于形成芯片设计+系统集成全栈自主可控链条,海光提供CPU/DCU算力核心与HSL芯片级互联,曙光提供超节点整机与scaleFabric系统级网络,实现从芯片到集群的全局优化。HSL协议起步速率112G(后续升级240G),带宽较PCIe提升8倍、时延降低50%,支持全局地址空间与缓存一致性,助力国产算力集群高效互联。
问题2:scaleX640与scaleX40两款超节点的定位差异与核心突破分别是什么?
答案:scaleX640定位超大规模高密度算力集群,核心突破是全球首个单机柜640卡部署,算力密度提升20倍,支撑10万卡级集群,解决万亿参数大模型通信瓶颈;scaleX40定位中小规模企业级训推,核心突破是全球首款无线缆架构,部署周期压缩至数小时,可靠性99.99%,降低算力落地门槛。
问题3:scaleFabric网络的技术壁垒与行业意义是什么?
答案:技术壁垒为全栈自研RDMA架构400G无损网络,覆盖物理层到应用层,交换芯片64Tbps吞吐、网卡时延<1us,兼容InfiniBand协议。行业意义是填补国内数据中心高速网络空白,实现“算-存-网”深度协同,解决万卡级AI集群通信耗时占比30%-50%的瓶颈,支撑国产超算与智算中心自主可控。






-389x550.jpg)







暂无评论内容