


Figure01最新视频表明了大语言-视觉模型介入人形机器人后,所带来的极快升级。近日人形机器人初创公司Figure公布其与OpenAI合作13天后的机器人最新视频,视频中OpenAI将其端到端的大语言-视觉模型移植到Figure01上,Figure01能够1)理解区分面前的场景对象;2)动作上区分苹果和一堆纸团;3)理解自身行为的目的;4)判断下一步的响应动作;5)评价自身行为;6)手指灵活度足够且动作较快。就目前所呈现的状态,我们认为人形机器人有望打开C端市场。
免费资源
© 版权声明
免费分享是一种美德,知识的价值在于传播;
本站发布的图文只为交流分享,源自网络的图片与文字内容,其版权归原作者及网站所有。
THE END







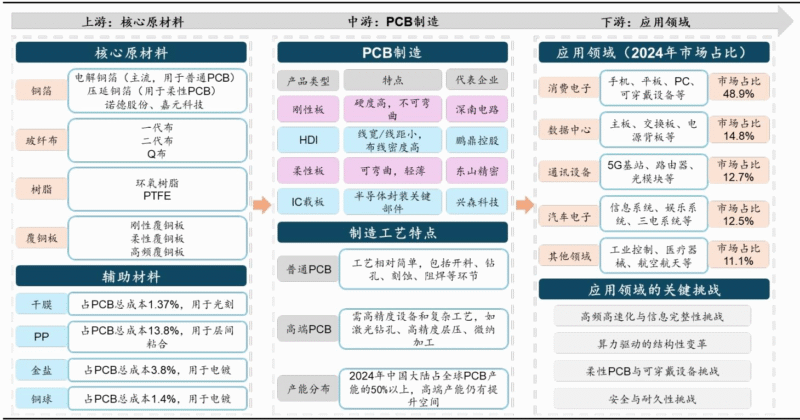
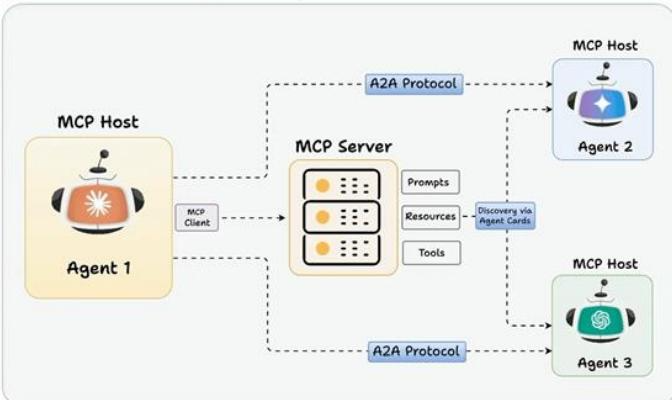
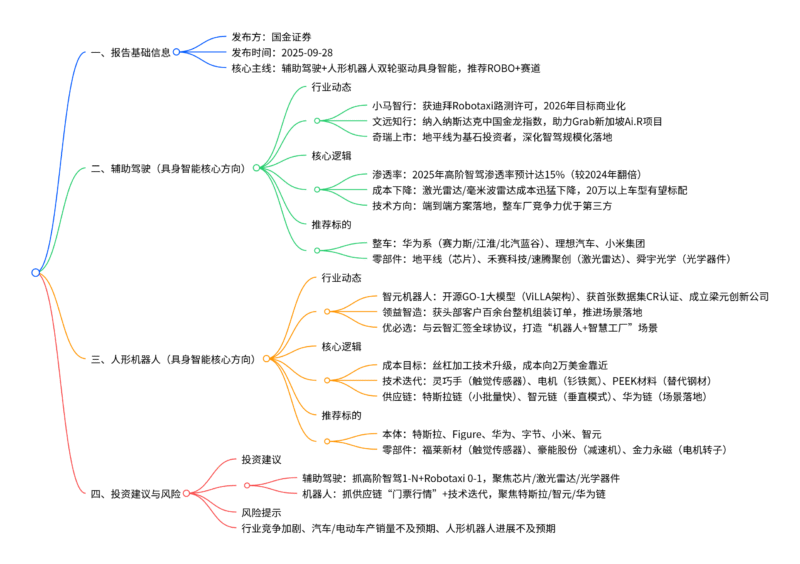




暂无评论内容